One of the things that is frustrating but really important to understand about coding political (or any) texts is how word usage varies by context. This is why sentiment dictionaries often perform poorly or have questionable validity. Human coding still really is the gold standard in terms of validity, but NLP has come a long way (ChatGTP!)
A new paper from Pedro Rodriguez, Arthur Spirling, and Brandon M. Stewart, “Embedding Regression: Models for Context-Specific Description and Inference,” demonstrates a way to use word embeddings to distinguish between how words are used differently by different users, such as politicians or political parties. Their paper is coming out soon in the American Political Science Review. From the abstract:
Social scientists commonly seek to make statements about how word use varies over circumstances—including time, partisan identity, or some other document-level covariate. For example, researchers might wish to know how Republicans and Democrats diverge in their understanding of the term “immigration.” Building on the success of pretrained language models, we introduce the à la carte on text (conText) embedding regression model for this purpose. This fast and simple method produces valid vector representations of how words are used—and thus what words “mean”—in different contexts. We show that it outperforms slower, more complicated alternatives and works well even with very few documents. The model also allows for hypothesis testing and statements about statistical significance. We demonstrate that it can be used for a broad range of important tasks, including understanding US polarization, historical legislative development, and sentiment detection. We provide open-source software for fitting the model.
The program, conText, is easy to implement in R. I ran through their tutorial using my own dataset (about 30 state party platforms from 2020). Their example for immigration worked well on my own dataset. I don’t have a lot of experience with word embeddings, so I used their pre-trained embeddings. Again, I am a novice at this, but I think because the pre-trained feature-embeddings contained most of the words used in the state party platforms, the results made sense. I like the program and their example. For those who use Quanteda, it is very similar (by design) and this made it easier to adjust when I ran into problems. In fact, it only took me about an hour or so to run through the immigration example, and then to also try another issue, abortion. I am definitely impressed. conText doesn’t need all that much user input. Just a few words are enough for it to comb through the corpus and pick out issue-specific words and also disentangle the partisan differences. For example, using nearest neighbors for “abortion” and setting the top 20 nearest words, produced the following:
Democratic words
A tibble: 20 x 4
target feature rank value
1 a legal 1 0.639
2 a access 2 0.579
3 a services 3 0.536
4 a provide 4 0.535
5 a including 5 0.531
6 a provides 6 0.480
7 a ability 7 0.460
8 a law 8 0.454
9 a federal 9 0.441
10 a funding 10 0.440
11 a health 11 0.438
12 a also 12 0.428
13 a women 13 0.425
14 a without 14 0.423
15 a care 15 0.418
16 a decision 16 0.418
17 a support 17 0.416
18 a rights 18 0.415
19 a information 19 0.413
20 a individuals 20 0.412
Republican words
A tibble: 20 x 4
target feature rank value
1 b human 1 0.610
2 b support 2 0.556
3 b child 3 0.506
4 b act 4 0.497
5 b legisl 5 0.464
6 b urg 6 0.464
7 b includ 7 0.458
8 b feder 8 0.455
9 b law 9 0.455
10 b public 10 0.454
11 b servic 11 0.454
12 b fund 12 0.453
13 b life 13 0.439
14 b provid 14 0.434
15 b also 15 0.431
16 b right 16 0.428
17 b children 17 0.419
18 b effort 18 0.412
19 b women 19 0.411
20 b author 20 0.409
(the word stemmings/lemmatization seems not to have been perfect). The idea is that “we know a word’s meaning by the company it keeps” and so differences in the nearest or most frequent neighbors indicate differences in partisan meaning. That said, it still largely picks out word differences (or differences in associations), and can’t necessarily provide insight into how the same word really is different. This is a point that they make in similar publications – researchers needs to make sense of the output and therefore expert knowledge and a good theory is necessary. Interpretation is for the researcher, not the machine. We can understand differences in the meaning of shared words (like “health”, “state”, or “government”), but this will require even more knowledge about the issues and how local (state) parties frame issues to make meaningful inferences.
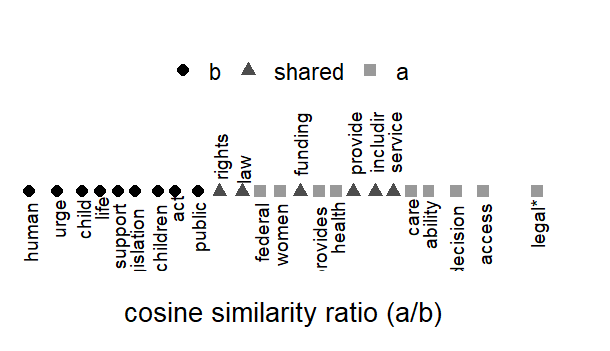
In the figure below, the Republican words associated with the use of abortion are on the left (I ran this quickly and didn’t get the chance to adjust the code to relabel the plot, hence the “a” and “b” in the plot), the Democratic words are on the right and the shared words (denoted by the triangle) are in the middle.
I’ve been reading Text as Data (Justin Grimmer, Margaret Roberts and Brandon Stewart, Princeton 2022) and I appreciate the clarity of their approach. I also appreciate the sentiment that they express repeatedly that the researcher needs theory to make sense of the text and they “emphasize throughout our book that text as data methods should not displace the careful and thoughtful humanist” (2022: 9). This is a point I will be coming back to over the next several posts: with so many options of NLP, why bother with human coding anymore? I think this is a question that needs attention and I this is something I will be focusing on during my fall sabbatical (it got approved!!!!) and on this blog.
Thanks for reading!
